贝叶斯个性化排序(BPR, Bayesian Personalized Ranking)是推荐系统中常用的一种推荐算法,它主要采用用户的隐式反馈(点击、收藏等)作为特征,通过对问题进行贝叶斯分析从而对item进行排序。
排序推荐算法分类
排序推荐算法可以大致被分为三类:
- 点对方法(Pointwise Approach),这类算法将排序问题转化为分类或者回归问题,再用现有的分类、回归方法进行实现。
- 成对方法(Pairwise Approach),所谓的pair就是成对的进行排序,比如有一对元素(a,b),pairwise的方法通过比较成对的元素进行排序。
- 列表方法(Listwise Approach),它在学习和预测的过程中都将排序列表作为一个样本,排序的结构被保持
BPR属于成对方法(Pairwise Approach)。
BPR建模思路
如下图所示,这是一个隐式反馈矩阵:
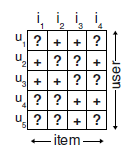
其中+代表用户对对应的商品产生了交互,?代表没有产生交互。
记用户为\(u\),物品为\(i,j\),当物品\(i,j\)同时存在时,用户\(u\)选择(点击、收藏等隐式操作)了\(i\),那么就得到了三元组\((u,i,j)\),它表示对于用户\(u\)来说,物品\(i\)排在\(j\)的前面。
为了方便表述,将三元组\((u,i,j)\)表示为\(i>_{u}j\), 有了这样的假设我们可以将用户-物品隐式反馈矩阵拆分成每个用户各自的物品排序矩阵: 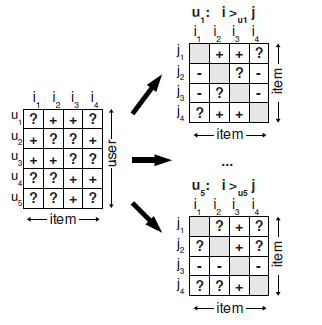
基于贝叶斯理论自然少不了独立性的假设,在BPR中有两个假设:
- 每个用户之间的偏好行为相互独立,即用户在\(i\)和\(j\)中的偏好与其他用户无关。
- 同一用户对不同物品的偏序相互独立,也就是用户\(u\)在商品\(i\)和\(j\)之间的偏好和其他的商品无关
在BPR中,这个排序关系符号\(>_{u}\)满足完全性,反对称性和传递性,即对于用户集\(U\)和物品集\(I\):
- 完整性: \(\forall i,j \in I: i \neq j \Rightarrow i >_{u}j \cup j>_{u}i\)
- 反对称性:\(\forall i,j \in I: i>_{u}j \cap j>_{u}i \Rightarrow i=j\)
- 传递性:\(\forall i,j \in I: i>_{u}j \cap j>_{u}k \Rightarrow i>_{u}k\)
BPR使用了矩阵分解方法来得到预测排序矩阵\(\hat{X}\):
\[ \hat{X} = WH^T \]
其中\(W^{|U| \times K}\)为用户矩阵,\(H^{|I| \times K}\)为物品矩阵,由于BPR是基于用户维度的,所以对于任意一个用户u,对应的任意一个物品\(i\)其期望为:
\[ \hat{x}_{ui} = w_u h_i = \sum_{j=1}^{k}w_{uj}h_{ij} \]
其中\(\hat{x}_{ui}\)表示物品\(i\)对于用户\(u\)的排序优先度。
BPR的算法优化思路
BPR基于最大后验估计\(P(W,H|>_{u})\)来求解模型参数\(W\)和\(H\),用\(\theta\)来表示参数\(W\)和\(H\),根据贝叶斯公式得到我们的优化目标:
\[ P(\theta|>_{u}) = \frac{P(>_{u}|\theta)P(\theta)}{P(>_{u})} \]
其中\(>_{u}\)代表用户\(u\)对应的所有商品的全序关系,由于全序关系已经确定,进一步来说可以得到:
\[ P(\theta|>_u) \propto P(>_u|\theta)P(\theta) \]
这个优化目标转化为了两个部分,其中第一部分与数据集\(D\)有关,第二部分无关。
对于第一部分,由于我们假设每个用户之间的偏好行为相互独立,同一用户对不同物品的偏序相互独立,所以有:
\[ \prod_{u \in U}P(>_u|\theta) = \prod_{(u,i,j) \in (U \times I \times I)}P(i >_u j|\theta)^{\delta((u,i,j) \in D)}(1-P(i >_u j|\theta))^{\delta((u,i,j) \not\in D) } \]
其中 \[ \delta(b)= \begin{cases} 1& {if\; b\; is \;true}\\ 0& {else} \end{cases} \]
根据完整性和反对称性,\((u,i,j) \in (U \times I \times I)\), \(P(i >_u j|\theta)^{\delta((u,i,j) \in D)}\)和\((1-P(i >_u j|\theta))^{\delta((u,j,i) \not\in D) }\)提供了相同的信息,那么在最大似然里只需要一个即可,第一部分可以简化为:
\[ \prod_{(u,i,j) \in D}P(i >_u j|\theta) \]
对于\(P(i>_{u}j|\theta)\)这个概率我们将其替换为: \[ \sigma(\hat{x}_{uij}(\theta)) \]
其中\(\sigma(\cdot)\)是sigmoid函数,由于\(\sigma(\cdot)\)有函数性质:
\[ 0.5 \leq \sigma(x) < 1 \quad \textbf{if} \quad x>0\\ 0 < \sigma(x) \leq 0.5 \quad \textbf{if} \quad x\leq0 \]
需要满足:
\[ \hat{x}_{uij}(\theta) > 0 \quad \textbf{if} \quad i>_{u}j \\ \hat{x}_{uij}(\theta) < 0 \quad \textbf{if} \quad j>_{u}i \]
因此我们可以设令\(\hat{x}_{uij} = \hat{x}_{ui} - \hat{x}_{uj}\),最终我们第一部分的优化目标从\(\prod_{u \in U}P(>_u|\theta)\)转化为:
\[ \prod_{(u,i,j) \in D} \sigma(\overline{x}_{ui} - \overline{x}_{uj}) \]
对于第二部分\(P(\theta)\),论文作者直接假设这个概率符合正态分布,且对应均值为0,协方差矩阵是\(\lambda_{\theta}I\),即:
\[ P(\theta) \sim N(0, \lambda_{\theta}I) \]
对于以上这个假设的多位正态分布,其对数和\(||\theta||^{2}\)成正比,即:
\[ \ln P(\theta) = \lambda ||\theta||^{2} \]
最后得到对数后验估计函数: \[ \begin{align*} \ln P(>_u|\theta)P(\theta) &= \ln \prod\limits_{(u,i,j) \in D} \sigma(\overline{x}_{ui} - \overline{x}_{uj}) + \ln P(\theta)\\ &= \sum\limits_{(u,i,j) \in D}ln\sigma(\overline{x}_{ui} - \overline{x}_{uj}) + \lambda||\theta||^2\; \end{align*} \]
最后使用梯度下降或者牛顿法等优化方法来求解模型参数即可。
BPR Loss
将BPR的思想拓展到损失函数上,就得到了BPR Loss,它的思想就是让正样本和负样本之间的分差尽可能大,具体公式如下: \[ L_{BPR} = -\frac{1}{N_{s}}\sum_{j=1}^{N_s}\log \sigma(r_i - r_j) \]